LogisticRegression From Scikit-Learn - Statistics Assessment
- University :
SWINBURNE UNIVERSITY of Technology Exam Question Bank is not sponsored or endorsed by this college or university.
- Country :
Australia
Task A
You will work on the credit risk defaulting classification task, using dataset Loans_Data_2019.xlsx. Variable descriptions are in LCDataDictionary.xlsx. debt_settlement_flag is the target variable.
1. Load the data and conduct exploratory data analysis.
Your analysis should present the distributions of features, discuss their properties, e.g. skewness and kurtosis, of features distributions, the relationship between features and the target, etc.
Please choose three most relevant features and present your results. Carefully explain your feature selection rules and criteria (No need to train a logistic regression model here).
2. Based on what we learnt in Lecture 9, write your own python code to implement the gradient ascent algorithm for the logistic regression with intercept:
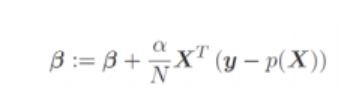 You also may consider feature engineering to make your algorithm more efficient and need to decide whether engineering the target variable.
You also may consider feature engineering to make your algorithm more efficient and need to decide whether engineering the target variable.
Use 4 features: "loan_amnt", annual_inc, int_rate and "installment".
Use ??(00) = [0, ... ,0] TT as your initialization point.
Find the approximate range of acceptable learning rates and explain why some learning rates are defective. You do NOT need to do train test split and cross
validation for this question, and only need to grid search a range of learning rates, based on your justified choice.
Find the optimal learning rate in this range and explain why this is the optimal learning rate and report your parameter estimates. You should decide your criteria of judging the optimal learning rate.
3. For this question, you can use LogisticRegression from scikit-learn. In Question 1, based on your exploratory analysis and domain knowledge in credit risk defaulting, you have selected the three most relevant features that best fit the logistic regression model for predicting the debt_settlement_flag.
Use train_test_split function to split 80% of the data as your training data, and the remaining 20% as your testing data. Use your selected three most relevant features, fit the logistic regression model with intercept with the training data, and generate the test set prediction performance (based on log-likelihood function value of logistic regression as below).
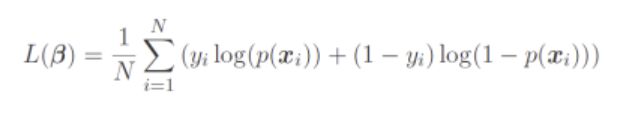 Task B
Task B
Some questions in Task B need you to do some self-learning, e.g., exploring how to build features for the text data using bag of words based on our lecture content. You should discuss with your group members on how to deal with the problem and do necessary self-learning which is an important ability to have for your future study and career.
Your goal is to build a Random Forest (RF) classifier that classifies whether a Youtube user comment is spam or not.
Use the user comments dataset Youtube_Comments.csv which contains the user comments of Youtube videos. "CLASS" in the data is the target variable.
(a) Use train_test_split function to split 80% of the data as your training data, and the remaining 20% as your testing data.
We have the feature data in the text format in column CONTENT. Therefore, now we need to transform the text feature into numerical features.
You can use the Bag-of-Words technique that we studied in the unit or other text mining techniques.
You can use any Python packages to complete the work and should decide the details of building the numerical feature space, i.e., how many features do you need, how to deal with
English stop words, etc.
(b) Now with the transformed data with numerical features, build a random forest classifier and use 5-fold cross validation to optimise the parameters of the random forest. You need to at least optimise the number of trees in the random forest and can explore and optimise other parameters as well.
