Building And Testing Classifiers In WEKA Task 3
- Country :
Australia
Task 3
Question 6
I tried five kind of trees for comparison of the performances. They are DecisionStump, J48, RandomForest, RandomTree, and LMT.
This table summarizes the performance of each classifier:
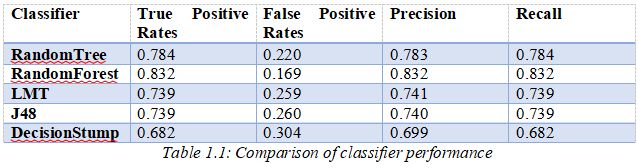
We can infer the following conclusions and explanations from the findings:
In comparison to the other classifiers, RandomForest and RandomTree produced greater True Positive Rates and lower False Positive Rates. This could be explained by the ensemble-based nature of random forests, which employ many decision trees that are aggregated after being trained on various subsets of data. Their greater performance was probably due to the ensemble technique, which tends to prevent overfitting and give better generalisation.
LMT and J48 have the same accuracy, precision and recall levels. Their learning algorithms, which both try to discover the optimum splits based on information gain or other criteria, may have some intrinsic commonalities that explain why they performed similarly.
DeicisonStump classifier performed the worst across all measures. Decision stumps are relatively shallow decision trees with a single split. On complex datasets, its simplicity frequently leads to low prediction power.
Question 7
The Random Forest classifier is selected as the best model or classifier for the wine quality dataset. The Random Forest classifier has the greatest accuracy rate of all the classifiers at 83.2%.
Following parameters yielded the best performance:
- bagSizePercent: 100
- batchSize: 100
- numIterations: 200
- K: 0
- M: 1.0
- V: 0.001
- S: 1
Justification of parameters and how they affect the classifier performance:
By utilising 200 trees, the Random Forest ensemble can decently balance reducing overfitting ( variance) and increasing accuracy. In general, adding more trees to the ensemble can improve performance, while doing so lengthens computation time.
Each tree will have been trained on all of the data currently accessible if the whole training set (100?g size) is used, increasing representation of the overall data distribution and reducing the likelihood of underfitting.
A batch size of 100 allows for more rapid training updates and may promote more consistent convergence. Smaller batch sizes may lead to more frequent updates, but they may also make the system noisier.
The present accuracy level was reduced when using any other set of parameter values. Therefore, using this parameter combination can help you get better outcomes.
Are you struggling to keep up with the demands of your academic journey? Don't worry, we've got your back! Exam Question Bank is your trusted partner in achieving academic excellence for all kind of technical and non-technical subjects.
Our comprehensive range of academic services is designed to cater to students at every level. Whether you're a high school student, a college undergraduate, or pursuing advanced studies, we have the expertise and resources to support you.
To connect with expert and ask your query click here Exam Question Bank
