Deep Learning Approach For NoSQL Query Regeneration Using XLNet Assessment
- Country :
Australia
1. Introduction
Non-relational databases are used by almost every industry of modern business. For massive data volumes, search engines, and real-time online applications, NoSQL databases are becoming increasingly popular. As an alternative to traditional databases like relational databases, NoSQL databases are widely used nowadays. Document stores, key-value data stores, wide-column stores, and graph stores are some of the NoSQL database types that have become increasingly popular as technology has advanced [1] [2]. The distributedsystem architecture is used by databases like MongoDB, CouchDB, Cassandra, etc. to store large amounts of data [3]. Slowly but surely, businesses everywhere are investigating methods to make sense of all this unstructured data. Big Data is revolutionizing the ways in which we manage, organize, and store our data [4]. In particular, the open-source architecture is knownas Big Data, which is used to store massive volumes of organized, unstructured, and semi-structured data.
To access and save a huge quantity of data, normal users must be familiar with the query syntax and table schema. Finding a trustworthy method to produce the NoSQL query in Natural Language (English), however, is difficult. The NoSQL methodology makes it possible for non-technical individuals to access and work with the database [21]. The paradigm simplifies human-machine interaction by eliminating the need to memorize a special query syntax to access non-relational data [5]. The study of how humans and computers work together with Natural Language (NL) is known as Natural Language Processing (NLP), which is a subfield of artificial intelligence, linguistics, computer science, and information engineering [6]. When converting one language to another through NLP, the text is translated using conventional machine translation [7]. The ultimate goal of this study is to create a workable instrument for database searching that makes use of plain language rather than requiring sophisticated database queries created by experts. There is a broad variety of uses for NoSQL code generated from natural language. The NLIDB system is used by AI-enabled tools for non-technical users, such as Google Assistant and Alexa. Instead of having to browse around the screen, search for values in a drop-down menu, and so on, users of NLIDB just put in a query in the form of a phrase [8] [25]. As a result, there are several contexts in which such a device may be useful.
The NoSQL methodology has been studied in both academic and business settings. In this research, we apply a four-stage paradigm for Neural Machine Translation. To begin, we have preprocessed text using a Natural Language Toolkit. The second step is to utilize the Levenshtein Distance (LD) method to gather and extract properties. Thirdly, we will use a fully connected encoder layers abstraction based on the XLNet Transformers Model to extract the aforementioned activities. The suggested method culminates in a stage called generating aquery.
Blank et al. (2019) presented similar work and the primary contribution of this study is the introduction of a fully trainable question-answeringsystem that facilitates the usage of natural language queries against an external NoSQL database [11]. The authors appliedpolicy-based reinforcement learning to the problem of non-differentiability in database operations, and the result is a respectable score on Facebooks bAbI Movie Dialogue dataset. The objective was to make database information accessible to a wider audience without requiring them to learn specialized query languages. The proposed research paper provides engineering efforts to begin a standard ML model and training procedure to all related structured database challenges via natural language questions.
Another similar study was presented by Yu et al. (2018) [13]. The authors put TypeSQL through tests using the WikiSQL dataset,it is stated that TypeSQL far outperforms the prior state-of-the-art on theWikiSQL dataset. Incorporating type information boosted performance by that amount, roughly 2%, for a cumulative gain of 5.5%. The methods of the Database community involve more hand feature engineering and user interactions with the systems. TypeSQLs content-sensitive model (TypeSQL+TC) gained roughly a 9% improvement compared to the content-insensitive model and outperformed the previous content-sensitive model by 17.5%; this is when scalability and privacy are not a concern [20].
1.1 Objectives of the research
Following are the objectives of this study:
- Designing algorithms to develop a machine translation model that can convert Natural Language into NoSQL queries.
- To implement the algorithm called Levenshtein Distance which can identify the content and characteristics from the text, irrespective of spelling errors or the use of synonyms.
- To improve the precision with which operations are extracted, we will use the most recent model of contextual word representation, XLNet Model.
1.2 Paper organization
The proposed research is structure in a manner that the first section provides introductory information about the topic understudy and its key concepts. Section 2 is dedicated to the literature review regarding the key terminologies and relevant researchers that have been conducted in a similar direction as the current research topic. Section 3, proposed methodology, in detail discusses the various steps and processes including explanation of XLNet model. Section 4 provides detailed analysis regarding the working of the XLNet Model in language processing and query generation; while the research is concluded with the 5 and last section providing the gist of the entire research.
2. Related Work
The study of Yan et al. (2021) found that the deep learning model for reinforcement learning functions by first choosing an ideal index for a predetermined fixed workload, and then adjusting to a dynamically changing workload [14]. The model adapts to new Q valuesand then uses those new Q values to inform its choice of index structure and those parameters. Note that the global optimum solution need not be the one that always chooses the action with the highest Q value. The primary takeaway from this research is that NoSQL databases can benefit from combining the index selection approach with deep reinforcement learning to more accurately choose the index that best suits the workload. The suggested NoSQL deep reinforcement learning index selection approach (DRLISA) was shown to operate well under a variety of workloads in an experimental setting. Traditional single-indexarchitectures predict varying degrees of performance improvement for DRLISA after appropriate training under fluctuating workloads.
In addition, Vonitsanos et al. (2020) provided that using a NoSQL database approach for modelling heterogeneous and semi-structured information has many advantages, such as the ability to deal with massive amounts of data, supporting replication and multi-data center replication, being scalable, being fault-tolerant, having a consistent query language, and so on [16]. Integrating Apache Spark with Apache Cassandra combines the best features of both platforms, making for a more powerful analytics framework. Apache Spark is a cluster computing system that provides a foundation and a growing ecosystem of modules to make complex data analytics practical. The NoSQL database Apache Cassandra is capable of offering highly available service with no single point of failure since it is designed to manage massive volumes of data. Combining these two technologies allows for the construction of a dataset utilizing data from many sources, as well as the development of a solid data analytics platform capable of handling massive datasets while offering highly available services with no single point of failure. Furthermore, the study of Lv et al. (2017) addresses the role of NoSQL databases in IoT big data processing [18]. The authors point out that many IoT systems use NoSQL as their primary database, making it the most likely data format for analyzing IoT large data. They also detail how some research projects have created a straightforward loading NoSQL system that enables the loading of standard conceptual programmes and permits the use of standard sources from which the data is expected to be obtained. In the end, the study offers practical ways for selecting a NoSQL system in which the conceptual program may be neatly structured. In conclusion, this study emphasizes the significance of NoSQL in analyzing big data in IoT systems and offers guidance on how researchers may develop efficient loading systems and select suitable NoSQL systems.
Wen et al. (2016) claimed that NoSQL is a popular alternative to traditional SQL databases. Some of its significant properties include flexible data models and scalable data storage [12]. These traits serve the demands of enormous workload online applications that may or may not have a preset structure. Due to its complex hierarchical data schema, the NoSQL database MongoDB was expressly selected to serve as a sample example. The data model of MongoDB is also discussed in this article. A document serves as the fundamental unit of data in MongoDB, and each document has a hierarchical and non-relational structure. Additionally, each document has a set of field/value pairs, and the value of a field may even be another document or an array. Documents stored in MongoDB are organized into one or more collections within a MongoDB database. The schema of a collection does not need to be set at the time the collection is being formed, which gives users additional data modelling flexibility to fit the design and performance needs of an application.
The study of Guo et al. (2020) discussed numerous challenges that must be overcome to create a reliable ranking system for massive volumes of natural language data [17]. The context and semantics of inquiries, profiles, and documents can be hard to capture due to the complexity and diversity of natural language. This is why there are two essential categories of deep NLP based ranking models: representation based and interaction-based models. Representation based models learn independent embeddings for the query and the document. DSSM averages the word embeddings as the query/document embeddings. Following this work, CLSM/LSTM-RNN encodes word order information using CNN/LSTM, respectively. Search systems also deal with massive amounts of data, so they need powerful algorithms and models that can process this information efficiently. Finally, boosting relevance performance sometimes incurs additional latency, therefore there is an equilibrium between effectiveness and efficiency in ranking algorithms. In light of these obstacles, it is clear that natural language processing models based on deep learning are necessary to accurately capture text semantics.
The study of Neves et al. (2021) shed light on a concept for an effective black-box monitoring solution for the comprehensive monitoring of distributed systems. Distributed applications including multiple components and multiple instances of each component are increasingly managed with containers, container pods, and container orchestrators. Distributed systems can use this method to keep tabs on how much data is being sent between different parts and instances of those parts without needing instrumentation or expertise in the underlying application [15]. A key issue in determining the performance of an application is the amount of data exchanged between different components. Using it in multi-platform micro services deployments, micro-bench marking its performance, and demonstrating its applicability for container placement in a distributed data storage and processing stack, the authors verify the prototype implementation. In addition, a thorough case study demonstrating how inter-application traffic may be exploited for container placement is presented in this article. This can be done either by the cloud platform itselfor manually by human operators.
According to Didona et al. (2018) integrating Machine Learning (ML) and Analytical Modelling (AM) approaches can result in performance prediction models that are more reliable and accurate [10]. ML-based modeling lies on the opposite side of the spectrum, given that it requires no knowledge about the target system/applications internal behavior. Specifically, ML takes a black box approach that relies on observing the systems actual behavior under different settings in order to infer a statistical behavioral model, e.g., in terms of delivered performance However, due to the fact that they are dependent on training data, ML models are known to have the potential to make inaccurate predictions. The authors offer three methods for merging AM with ML in order to overcome this issue: ensemble learning, hybrid modelling, and feedback-based modelling. In order to lower the likelihood of either over fitting or under fitting, ensemble learning involves integrating numerous machine learning models that were trained using distinct data sets or techniques. AM and ML are both components of hybrid modelling. In hybrid modelling, AM is used for the components of the system that can be modelled analytically, while ML is used for the components of the system that are difficult to represent analytically [19]. Modelling that is based on feedback entails modifying the predictions made by the model depending on information obtained from the actual performance of the system.
The study of Haghighian Roudsari et al. (2021) evaluatedthe efficacy of fine-tuning previously trained language models for multi-label patent categorization [9]. In particular, they evaluate the efficacy of four pre-trained language models (BERT, XLNet, RoBERTa, and ELECTRA) by contrasting it with the performance of baseline deep-learning techniques that are utilized for patent categorization. However, applying traditional methods for text processing has not effectively processed patent text and efficiently extracted properties from it for patent classification search, and retrieval. The performance of the baseline models is improved because of the authors utilization of a variety of word embeddings. Experiments wererun using theUSPTO-2M patent categorization level and M-patent datasets, both of which were available to the public. The USPTO-2M is a large-scale patent categorization level made openly. The USPTO-2M is obtained from a large size of data accessible online in United States (US) Patent and Trademark Office website. According to the findings, optimizing language models that have already been pre-trained using patent text can increase the effectiveness of multi-label patent categorization. XLNet gets an updated state-of-the-art categorization functioning, outperforming the other three pre-trained language models in terms of accuracy, recall, and F1 measure, in addition to coverage error and LRAP. It also has the best performance when compared to LRAP and coverage error.
3. Proposed Methodology
NL is converted into NSQL by utilizing NLTK in conjunction with a Deep Learning Model. This is the primary idea that underpins this technique. The next parts provide a formalization of the notion and its definition. In Fig. 1 we can see the suggested architecture.
A. NLQ (Natural Language Query).
No extra syntax or formatting is required for NLQ; it just consists of the user's everyday language. The inquiry is written in English and is a natural language query (NLQ). The text you provide will be parsed into NoSQL queries that may be used to get data.
1. Text preprocessing
Words can be combined into sentences, paragraphs, or special letters. Text preprocessing is crucial to NLP model construction. Data mining turns raw text into amachine-readable format. Real-world data often lacks particular behaviors and contains inaccuracies.This stage converts human-language input to machine-readable form for processing.
2. Text Tokenization
Tokenization is the process of breaking down a NLQ, phrase, string, or document into its component parts, often words. A list of sentences is a common use of the now-defunct Sentence Boundary Disambiguation (SBD). It uses a language-specific, pre-trained algorithm, much as NLTK's Punkt Models. Using an unsupervised approach, a model for shortened words is constructed from the text's list of terms. The NLTK data package has a pre-trained Punkt tokenizer for the English language.
3. Word Escape
Escape words, also known as superfluous words, are words that appear often in a document but add nothing to its meaning or context. Because they are notnecessary for the analysis of the query, the escape words are omitted. Several different lists of escape words have been developed for use in constructing queries. In this study, we put forth a different vocabulary for "escape" situations. Auxiliary verbs and prepositions like a, an, the, is, of, with, to, for, and, all, etc. are frequently employed as "get out of jail free" cards in this situation.
In the present study,a four-stage process for Neural Machine Translation is suggested (Figure 1). We begin with text preparation by using a Natural Language for user query. Second, the Levenshtein Distance (LD) technique will be used to gather and extract data characteristics and attributes. Finally, to extract the aforementioned actions, we will employ a fully linked encoder layers abstraction from XLNet Transformers Model-based multi-text categorization. The suggested method will be concludedin a phase labelled generating query. The idea behind this technique is to use a Deep Learning Model to move to NSQL from NL. In the following sections, we haveformalizedthe idea and describe it in detail, figure 1 depicts the suggested architecture.
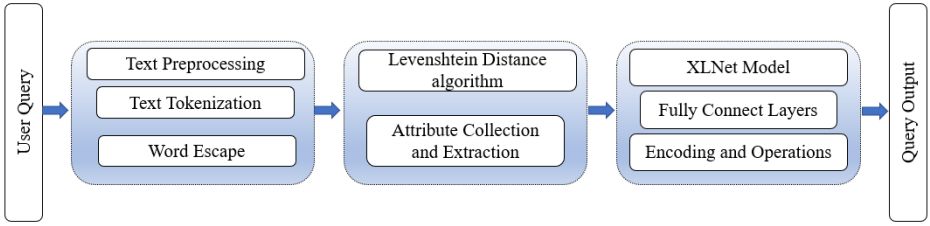
Figure 1: Proposed Methodology
Attribute Collection and Extraction Phase
Within a particular solution, the LD algorithm is utilized in order to extract collections and attributes from natural language queries. Counting how many terms are similar is the first step. Then, the LD compares every similar word with every attribute from the WordNet, and the synonym list helps extract attribute and collection names. This approach stores noun tag synonyms. WordNet generates noun tag synonyms. Synonym lists find a collection and attribute from an input query. User queries vary. They utilize various terminologies to define attribute or collection names. This method searches WordNet for user query synonyms. LD is a threshold in this study.If the value of a sentence word exceeds a predetermined threshold, the collection and its corresponding attributes are stored in a database under the corresponding name.
TABLE I: COMPARISON OF TEXT DETECTION WITH INTRUSION DETECTION USING THE LD ALGORITHM
| Text | Intrusion Detection |
|---|---|
| Find the name of all entities (for e.g., employee) | Collection(all_employees) |
| What is the (for example) address of employee id 01 | Attribute(address) |
| Find the first name of the employees | Attribute(name) |
C. Encoding and Operations using XLNet
XLNet, an innovative language model, captures intricate linguistic interactions with its unique encoding and feature extraction. XLNet encodes and extracts using permutation-based encoding and autoregressive feature extraction. XLNet permutates the input sequence in the permutation-based encoding stage. This approach overcomes the Transformer's token-only constraint. XLNet optimizes bidirectional dependencies by examining all permutations. Pretraining samples these variations to give the model alternative perspectives [22] [24]. Figure 2 shows the encoding and operations process while employing XLNet.
XLNet uses the transformer architecture for each permutation during autoregressive feature extraction. The model estimates the probability distribution of each token based on its predecessors, capturing contextual information. XLNet models bidirectional dependencies by attending to both the left and right context of each token using masked self-attention methods.
In addition, XLNet uses autoregressive language modeling. XLNet uses permutation language modeling to predict the future token depending on the preceding tokens, unlike standard models [23]. XLNet is a generalized autoregressive pre-training model, was proposed to address the weak points of the BERT model. XLNet utilizes permutation language modeling instead of MLM, which also makes it possible to capture bidirectional context. Further, XLNet also captures document-level relationships via segment-level recurrence. The concept preserves coherence within segments while facilitating information flow between segments by splitting lengthy texts into small parts [25]. This method helps the model grasp and summarize long texts.
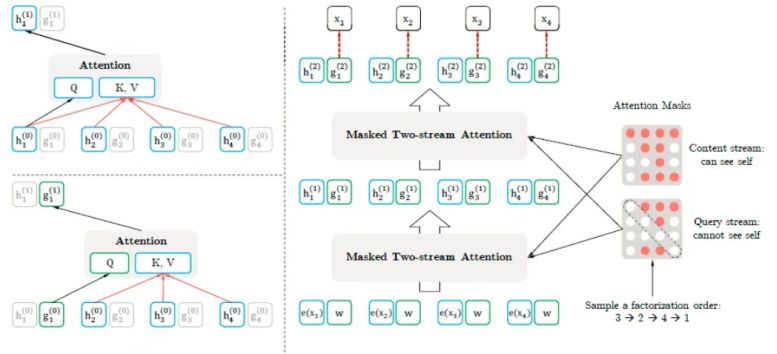
Figure 2: Encoding and Operations using XLNet
Finally, the individual steps are linked together to produce a NoSQL query. Figure 3depicts the structure of a NoSQL query and the result that is returned.

Figure 3: Architecture of Query Generation
4. Discussion and Analysis
Using a sophisticated Deep Learning Model and the Natural Language Tool Kit (NLTK), we will convert NL to NSQL, or non-structured query language. The way we engage with information may be permanently changed by this method. The next several paragraphs provide a more formalizeddescription of this idea.
Natural Language Query
In the future, NLQ will only demand the user to utilize their natural language without any special syntax or formatting. The question will be formulated in English and will operate as an NLQ. NoSQL queries based on the inputted text will be generated and utilized to get the specified information.
Text Preprocessing
The words will be connected together to form phrases, paragraphs, and symbols. For the foreseeable future, text preparation will be essential while developing NLP models. Data mining will keep on converting unprocessed text into a machine-readable format. Inaccuracies and the absence of consistent patterns are common in real-world data. In this step, theinformation provided in human language will betransformed into a format that computers can understand.
Tokenization
Natural language queries, strings, and documents will still require tokenization to be broken down into their individual words. The now-defunct Sentence Boundary Disambiguation (SBD) will continue to be widely applied to lists of sentences. Using a language-specific, pre-trained method, such asNLTKs Punkt Models, will be required. The list of words in the text will be utilized to train an unsupervised model to deal with abbreviations. The NLTK data package includes an English-speaking Punkt tokenizer that has already been trained.
Word Escape
Those words that are used frequently but contribute nothing to the meaning or context of a document are called escape words. These escape words will not be included in the query analysis because they are not required. For the purpose of constructing queries, several lists of escape words will becompiled. The purpose of this research is to suggest a new set of words for dealing with such escape scenarios.
There will be four phases intotal to theresearch into Neural Machine Translation. The process will beginwith a round of Natural Language-based textpreparation for the user's inquiry. Second, we'll be working on collecting and extracting data features and attributes using the Levenshtein Distance (LD) approach. Finally, we will use the XLNet Transformers Model for multi-text classification, which is built on a fully linked encoder layers abstraction, to extract the aforementioned behaviors. The suggested procedure will end with a step called "generating aquery." The concept behind this method is to use a Deep Learning Model to translate between Natural Language and Unstructured Query Language.
Attribute Collection and Extraction- use of Levenshtein Distance (LD) Algorithm
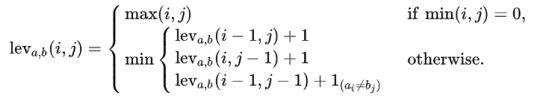
Figure 4: Levenshtein Distance (LD) Formula
When comparing two strings of length n, the Levenshtein distance between them can be calculated to within a factor of n.
(Log n) O (1/ ?)
where?> 0is a free parameter to be tuned, in timeO (n1 +?).
Computational Encoding and XLNet-Based Operations
XLNet, a language model, can capture complicated interactions due to its encoding and feature extraction. XLNet uses autoregressive feature extraction and permutation-based encoding. XLNet permutation-based encoding randomly shuffles the input sequence. This circumvents the Transformer's token-only restriction. XLNet will do everything to discover the best bidirectional dependence. Pre-training will sample these alternatives to give the model more input.
XLNet uses transformer architecture for all forms of autoregressive feature extraction. Based on what occurred before, the model will make a plausible guess based on token probability distribution. XLNet will define bidirectional interactions using masked self-attention approaches.
XLNet will employ autoregressive language modeling. Permutation language modeling will predict the future token based on previous tokens, unlike standard models. The model will record relationships irrespective of token sequence to benefit downstream tasks including text categorization, named entity identification, and machine translation.
XLNet will also reconnect document segments. The goal is to divide large texts into digestible parts while retaining internal consistency and encouraging dialogue between chunks. This will help the model comprehend and synthesize long texts.
Encoding using XLNet
Input Sequence: X = {x1, x2, ..., xn}
Permutation: P = {P1, P2, ..., Pk}
Encoding Output(xi) = aggregate([Ve(xi), Pe(i), attention_scores(xi, :)])
Token embeddings: Ve(xi)
Positional encodings: Pe(i)
Attention mechanism: Att(xi, xj)
XLnet formula
max ?t=1 to T ?z log p? (Xz1 | Xz_1:t-1)
In this expression, T is the maximum length of the sequence, t=1 to T is the sum over t from 1 to T, and z is the sum over all latent permutations. The log of the conditional probability of the t-th element Xz1 given the prior items Xz_1:t-1 is denoted by z.
