COMP1702 Big Data Assignment
- Subject Code :
COMP1702
- Country :
Australia
Part A (25 Marks)
- Task A.1 [mark 10] Explain the main characteristics of Big Data. (Word count: 200 words 10%)
- Task A.2 [mark 15] Compare Hadoop and Relational Database Systems. Give an application scenario that is well suited to Hadoop and explain your reason. (Word count: 300 words 10%)
Part B (30 Marks): MapReduce Programming
Suppose that there is a computer science bibliography file stored on Hadoop. Each line of this file contains information of a paper in the following format:
authors|title|conference|years
The different fields are separated by the | character, and authors (the first field) are separated by commas (,). You can assume that there are no duplicate records, and each distinct author or conference has a different name.
An example line is:
D Zhang, Daniel H, D Cai, J Lu|Self-Taught Hashing for Fast Similarity Search|SIGIR|2010
Please design a MapReduce algorithm (using Pseudo-codes or Java Codes) to output the number of papers by each author in each year if the number is large than 0.
The algorithm is expected to be as efficient as possible.
You should also explain how the input is mapped into (key, value) pairs by the map stage, i.e., specify what is the key and what is the associated value in each pair, and, how the key(s) and value(s) are computed. Then you should explain how the output (key, value) pairs of the map stage are processed by the reduce stage to get the final answer(s). You need to discuss the efficiency of your algorithm (How your design make your algorithm efficient). (Word count: 300 words 10%)
Part C (45 marks): Big Data Project Analysis
The CropY company is a leading provider of precision agriculture service. Precision agriculture is the science of gathering, processing, and analyzing temporal, spatial and individual data. It combines other information to support management decisions according to estimated variability for improved resource use efficiency, productivity, quality, profitability.
The CropY company is now plan to develop a big data project to meet the following requirements: help worldwide users better understanding the implications of the weather and making contingency plans; buying supplies, such as fertilizer and seeds; as well as maintaining and monitoring the quality of yield, whether livestock or crops; knowing the variety of cultivated plants, conditions of its growth and its needs of seeds; choosing the type of fertilizer and pesticides, understanding their employment conditions and their impact on the climate- soil-plant; recognizing daily water needs for each kind of plant; calculating the median and mean values of yield; studying the conditions of natural environment; estimating the financial revenue and manage the potential risks.
Task C.1 [mark 10]:
The volume of big data is expected to be more than 500 Petabytes. The data will come from various sensors, satellites, drones, social media, market data, Online news feed etc. The Figure 1 below shows some example data of CropY company. Some IT technician plan to build a data warehouse to store data for further data analysis tasks but some others believe data lake is a better choice. Which choice do you prefer? Please justify your choice. (Word count: 300 words 10%)
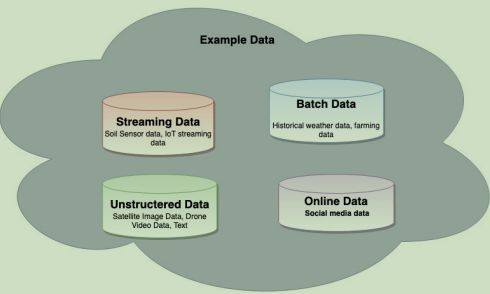
Figure 1. Example Data of CropY Company
Task C.2 [mark 10]:
The data of CropY company includes a large collection of plants, corps, diseases, symptoms, pests, and relationships between them. The CropY company needs to build a data analytical store which can facilitate queries like: find all diseases which are directly or indirectly caused by nitrogen deficiency. Please recommend a data store and justify your choice. (Word count: 300 words 10%)
Task C.3 [mark 15]:
Some prediction and analytic services provided by the CropY company require to response in a few seconds after the arrival of new data. Namely, they are real time or near real time prediction and analytics tasks.
Some IT managers suggested a popular distributed processing framework MapReduce to implement these tasks. Do you agree with that? Or you have different suggestion. Please justify your choice. (Word count: 300 words 10%)
Task C.4 [mark 10]:
CropY company decided to move most of applications and services to cloud. These applications and services need to be highly available, scalable, and accessible from worldwide. Note that some data such as price and customer data are confidential. Please design a cloud hosting strategy for this big data project and explain how your design will meet the security, scalability, high availability. (Word count: 300 words 10%)
Are you struggling to keep up with the demands of your academic journey? Don't worry, we've got your back! Exam Question Bank is your trusted partner in achieving academic excellence for all kind of technical and non-technical subjects.
Our comprehensive range of academic services is designed to cater to students at every level. Whether you're a high school student, a college undergraduate, or pursuing advanced studies, we have the expertise and resources to support you.
To connect with expert and ask your query click here Exam Question Bank
