Web Crawling and Natural Language Processing COMP3450
- Subject Code :
COMP3450
Assessment3:WebCrawlerandNLPSystem
Type:WrittendocumentandJupyterNotebook
Weight:50%
Length:Upto3000wordswrittendocument,excludingcode,references,andoutput
Overview
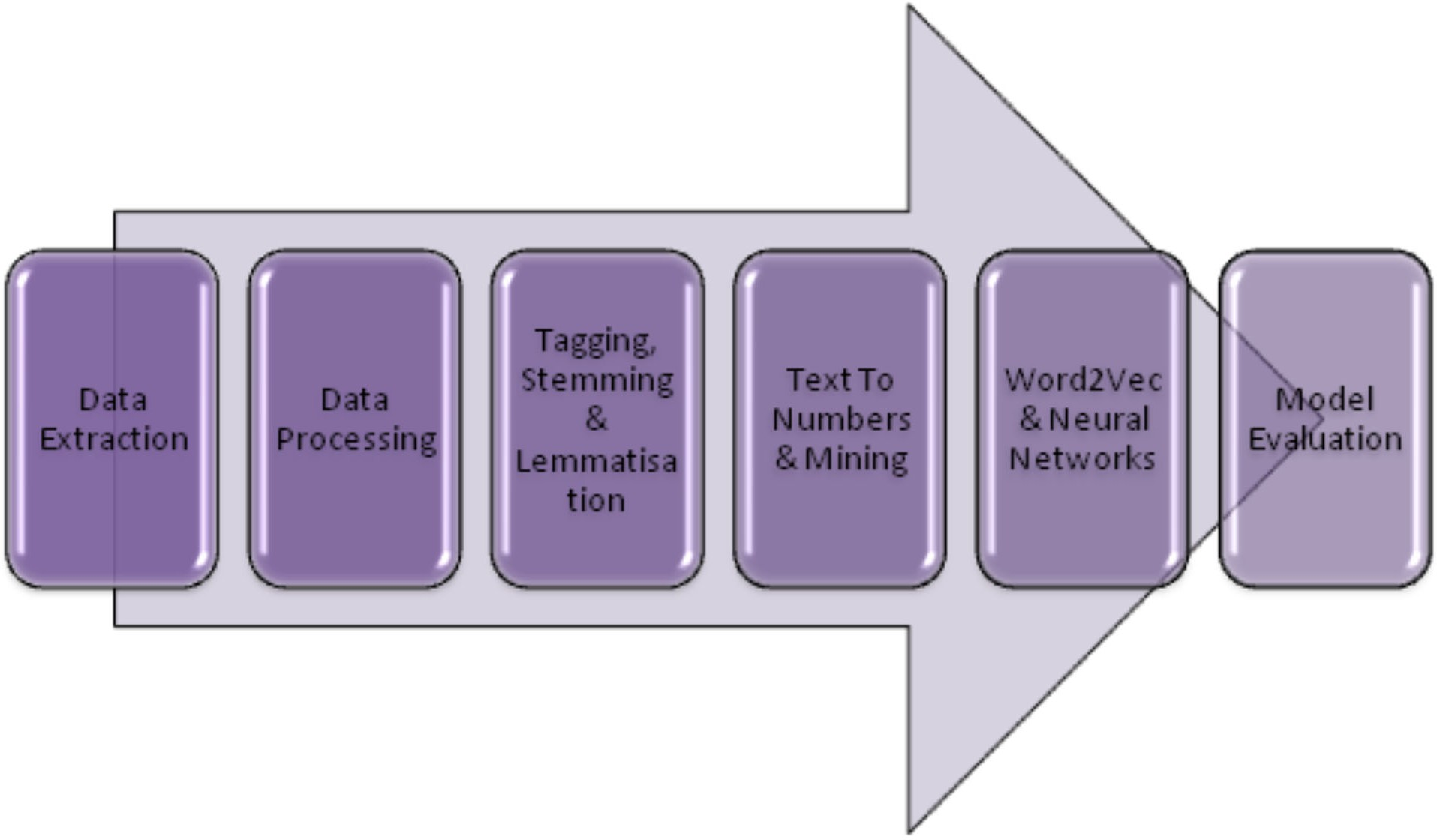
This assignment involves building a prototype NLP solution using web scraping and machine learning. The initial part of the NLP solution is gathering data using a web scraper. The web scraper collects information from relevant websites and supplements that website data with metadata from additional knowledge databases (if needed). Once the data for the NLP solution is gathered, the data need to be processed, cleaned, and normalised.
A part of modern text normalisation is using machine learning are word embeddings. Word embeddings are a type of word representation that allows words with similar meaning to have a similar representation. Word embeddings are a distributed representation for text that is perhaps one of the key breakthroughs for the impressive performance of machine learning methods on challenging natural language processing problems.
To assist a development team integrating your WebCrawler and machine learning task, you willneedtopublishyourdocumentationandcodeinaGit-repository.
Learningoutcomes
- Apply NLP data science skills, knowledge, and techniques to solve problems in data science NLP projects with a focus on web crawler and content extraction from
- Apply NLP tasks in Python
- Understand how to deploy data science projects into production pipelines
Deliverables
Forthisassessment,youaretoproduceareportdetailingallfourtasksANDaJupyter Notebook file with the final version of the Python code used.
Tasks
Thisassessmentcomprisesoffourtasks
- Defining of a single issue to be investigated or address using NLP methodologies
- Sourcing data from webpages and supplementing data from knowledge sources relevant to the issue
- Dataw rangling: Cleaning, normalisation, feature extraction of the sourced Normalisationmayinclude applying a word embedding algorithm.
- Modelling usingmachinelearningandvaluationofthe
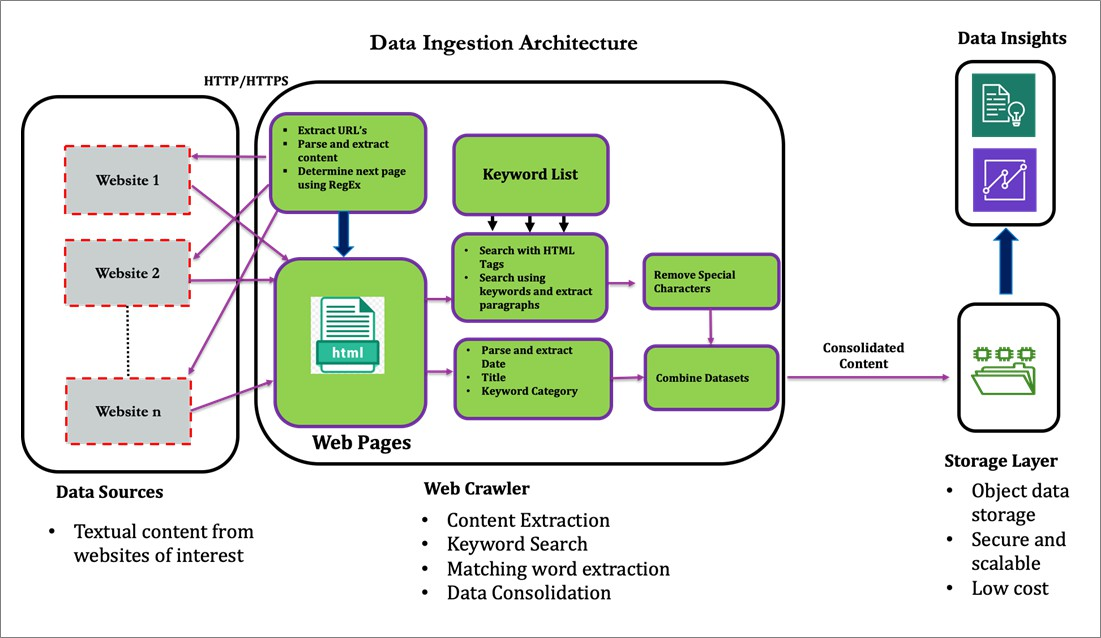
Figure1https://aws.amazon.com/blogs/apn/gathering-market-intelligence-from-the-web-using-cloud-based-ai-and-ml-techniques/
TaskDescriptions
Task1.Overview:Length:<200words(excludingcodeandreferences)
- An over view of the Issue
- Where the Issue is present on the world wide web
- How machine learning can be applied to provide a solution to the Issue
Task2.WebCrawler:Length<500words(excludingcodeandreferences)Detailing
- Websites
- Website/datacopy right considerations
- Methodology of applying the web crawler/scraper
- Limitations of the WebCrawler and the harvested
- Methodology of storing harvested data
Task 3.DataWranglingLength<500words(excludingcodeandreferences) Detailing:
- Cleaning, normalisation, feature extraction of the sourcedNormalisation may include applying a word embedding algorithm
- Summary and visualisation of the harvestedPreliminary EDA is acceptable in this section as well.
Task 4.MachineLearningLength<800words(excludingcodeandreferences) Detailing:
- Specification and justification of the implementation of the ML model
- Evaluation and visualisation of the machine learning model performance
- Effect of the data limitations and sampling biases on the machine learning performance
Wordlengthsarerecommendationsandmaychangerelativetoyourreportingneeds.
Permittedguidelinesforwebscraping
- Public dataonly:Availabletoanyoneonthewebwherenothinginthedataisbehind any kind of walled garden, pay or otherwise.
- Previously allowed:Some sites that have tacitly accepted that scraping occurs. For example, some services are openly acknowledged that this occurs (e.g. media intelligence and media monitoring).
- Non-copyright-protected content:The data involved appears to mostly, if not exclusively, be facts and information not protectable under copyright.
Permitted use of copyright-protected:If the site has a copyright protection notice, thenthe material scraped must be within the permissible use. Normally there is a standard notice onawebsitethatwillallowtodownload,display,printandreproduceitsmaterialinunaltered form only, provided that appropriate acknowledgment is made for your personal, non- commercial use. Take, for example,James Cook University website copyright and terms ofuse. James Cook Universitys copyright states that using areading list for metadata analysis would be possible as long as an appropriate acknowledgement is made
NOTES:SizeofCorpus
The NLP system is a prototype so the number of documents in the corpus will be limited in size.However,thesizeofthecorpuswillneedtobesufficienttodemonstratetheissueand tocalculatequalitymetrics.Asanindicativeguide,thenumberofdocumentsinyourcorpus will depend on the length of the documents.
- Small lengthdocumentssuchassocialmediaposts,postsondiscussionboardsor phone text messages, you can expect to have 500 to 1000 documents in your
- Medium lengthdocumentssuchasonlinenewarticlesorextractsfromreports(or long documents) you can expect to have 100 to 300 documents in your corpus.
- Long lengthdocumentsuchascompletecompanyreports,youcanexpecttohave 50 to 200 documents in your corpus.
NOTES: Cloud Flare
Website may use technologies that actively prohibit web scraping to protect IP or to mitigate potential website downtime due to denial of service (DOS). Web scrapers and web crawlers can cause DOS outcomes. Cloud Flare is a very common technology that is used to keep a website operating by preventing headless web browsing scraping, like Selenium and Scrapy.
YoucancheckifawebsiteisprotectedbyCloudFlareatsiteslikehttp://www.doesitusecloudflare.com/
Assessmentsubmissionguidelines
UseMSWordorPDFforthewrittenreport.
Your submission for Assessment 3 should be uploaded to Learn JCU as two (2) separate files:
File1thewrittenreport.File2theJupyterNotebook.Yourreportmeetingfollowing requirements:
- File name: pdf (or *.ipynb)
- 12ptfontsizewithsinglelinespacing(preferred)
- APA referencing style applied (preferred)
Youmayuploadasmanytimesasyouwant,butonlythelastsubmissionisgraded.
Importantnote
Theentire projectmust be accomplished usingPython. Any calculations, visualisations, resultsandsoonproducedusingsoftwareotherthanPython(e.g.R,Excel,Tableauetc.)isnotaccepted and, therefore, will not be assessed. The code itself must be prepared usingPython either as a script in notebook form or standalone Python files. Refusal to comply with these requirements will result in your work being considered asnot delivered.
Markingcriteria.Task 1:Overview10% ofOverallgrade
|
Criteria |
HighDistinction/Distinction:Sophisticated/Exceeds Expectations (75-100%) |
Credit/Pass:Above/MeetsExpectations(50-74%) |
Fail: Unsatisfactory / BelowExpectations(0- 49%) |
|
Overview 100%ofsectiongrade |
Identifiesanddiscusses: TheIssue WheretheIssueispresentontheworldwideweb,withlinkages to how the chosen domains could be expanded Howmachinelearningcanbeappliedtoprovideasolutionto the Issue with a brief literature review of peer reviewed literature relevant to the chosen NLP machine learning task;
DiscussionsarespecificandtargetedtowardsclearlyidentifiedaNLP task.Discussions are supported with credible references sources. |
Identifiesanddiscusses: TheIssue WheretheIssueispresentontheworldwideweb Howmachinelearningcanbeappliedtoprovidea solution to the Issue
DiscussionsareinageneralnatureofNLPtasksroutine data science related situation. |
Partially identifies and/or explainssomekeyissuesin a superficial data science related situation |
Markingcriteria.Task2:WebCrawler30%ofOverallgrade
|
Criteria |
HighDistinction/Distinction:Sophisticated/Exceeds Expectations(75-100%) |
Credit/Pass:Above/MeetsExpectations(50-74%) |
Fail:Unsatisfactory/Below Expectations(0-49%) |
|
Domains 25%ofsectiongrade |
Identifiesanddiscusseswithjustifications: WebsiteURLstobecrawledwithconsiderationof:coverageof the chosen domains on the issue relative to the www; limitations of the consumeddomains withlinkages to sampling design and ethical considerations Copyrightofthechosendomainsandlinkagestoappropriate legal frameworks TheNaturalLanguagedata,meta-data,orotherdataoneach domain and how these data align to the issue Discussionsareinacomplexdatasciencerelatedsituation, drawing upon relevant theory from a wide range of credible sources; eliciting insightful knowledge linking to broader relationships and, bring in originality of perspective |
Identifiesanddiscusses: WebsiteURLstobecrawled Copyrightofthechosendomains ThetypeofNaturalLanguagedatausedinthe domains. Discussionsaregeneralinnatureandidentifymost criteria |
Partially identifies and/or explains somekeyissuesinasuperficialdata science related situation |
|
WebCrawler workflow
75%ofsectiongrade |
Identifiesanddiscusseswithjustifications: Technologycomponentsusedforthewebcrawlerwith comparisons to other similar technology components Complexityofthedomainsandwherethetargeteddata resides Methodologyandsequencingofthecrawler(s),using the complexity, data structures and website access restrictions to optimise the crawler Datastorage |
Identifiesanddiscusses: Technologycomponentsusedfortheweb crawler Wherethetargeteddataresidesonthe domains Methodologyandsequencingofthe crawler(s) Datastorage |
Partially identifies and/or explains somekeyissuesinasuperficialdata science related situation |
|
Discussionsareinacomplexdatasciencerelatedsituation, drawing upon relevant theory from a wide range of credible sources; eliciting insightful knowledge linking to broader relationships and, bring in originality of perspective |
Discussionsareinaroutinedatasciencerelated situation,usingcodeextractsindiscussionsand demonstrations, drawing upon relevant theory |
Markingcriteria.Task3:DataWrangling. 20%ofOverallgrade
|
Criteria |
HighDistinction/Distinction:Sophisticated/ExceedsExpectations (75-100%) |
Credit/Pass:Above/MeetsExpectations(50-74%) |
Fail:Unsatisfactory/Below Expectations(0-49%) |
|
DataWrangling
50%ofsectiongrade |
Identifiesanddiscusseswithjustifications: Corpusdatawranglingmethodsthatbegintofeatureengineer towards the intended NLP task FeatureextractionappropriatetotheintendedNPLtask Hyperparametersofthefeatureextractiontask Generationofanappropriatetrainingandtestsetswithreferenceto any sample distributions, biases and or data limitations ? Discussionsareinacomplexdatasciencerelatedsituation,drawing upon relevant theory from a wide range of credible sources; eliciting insightful knowledge linking to broader relationships and, bring in originality of perspective |
Identifiesanddiscusses: Cleaningandnormalisationofthecorpus Featureextractionappropriatetothe intended NPL task Discussionsareinaroutinedatasciencerelated situation,usingcodeextractsindiscussionsand demonstrations, drawing upon relevant theory
? |
Partially identifies and/or explainssomekeyissuesina superficial data science related situation |
|
DataSummarisation
50%ofsectiongrade |
Identifiesanddiscusses: Visualisationandinterpretationofsampledistribution Visualisationandinterpretationofcorpus Descriptivestatisticsofboththesampleandthecorpus Corpuslimitations Samplingbiases Discussionofthecorpusareinclusiveofpopulationsampling considerations and population strata.
Discussions, visualisations and tabulations contain linkages to samplingdesignandlimitations/designfeaturesofthewebcrawler. Discussionselicitinsightfulknowledgelinkingtobroader relationships and, bring in originality of perspective |
Identifiesanddiscusses: Summaryofthegeneratedcorpus Visualisationofthecorpus Descriptivestatisticsofthecorpus Discussionsareinaroutinedatasciencerelated situation,usingcodeextractsindiscussionsand demonstrations, drawing upon relevant theory |
Partially identifies and/or explainssomekeyissuesina superficial data science related situation |
|
Criteria |
HighDistinction/Distinction:Sophisticated/Exceeds Expectations(75-100%) |
Credit/Pass:Above/MeetsExpectations(50-74%) |
Fail:Unsatisfactory/Below Expectations(0-49%) |
|
Machine learning Structure 50%ofsectiongrade |
Identifiesanddiscusseswithjustifications: Structureofthemachinelearning Hyperparametersofthemachinelearningalgorithm Computationenvironment Discussionsareinacomplexdatasciencerelatedsituation, drawing upon relevant theory from a wide range of credible sources; eliciting insightful knowledge linking to broader relationships and, bring in originality of perspective |
Identifiesanddiscusses: Structureofthemachinelearning Hyperparametersofmachinelearningalgorithm Computationenvironment Discussionsareinaroutinedatasciencerelated situation, drawing upon relevant theory |
? Partially identifies and/or explains somekeyissuesinasuperficialdata science related situation |
|
Evaluation
50%ofsectiongrade |
Identifiesanddiscusses: Detailedevaluationofthemachinelearningperformance Visualisationofthemodelperformance Detailedeffectsofthedatalimitationsandsamplingbiases on the machine learning model performance
Discussionsareinacomplexdatasciencerelatedsituation, highlights potential downstream effects related to data distribution,missingdata,ordatabiases.Discussionselicit insightful knowledge linking to broader relationships and, bring in originality of perspective |
Identifiesanddiscusses: Preliminaryevaluationofthemachine learning performance Visualisationofthemodelperformance Someeffectsofthedatalimitationsandsampling biases on the machine learning model performance
Discussionsareinaroutinedatasciencerelated situation,usingcodeextractsindiscussionsand demonstrations, drawing upon relevant theory |
Partially identifies and/or explains somekeyissuesinasuperficialdata science related situation |
|
Criteria |
HighDistinction/Distinction: Sophisticated/ExceedsExpectations(75-100%) |
Credit/Pass:Above/MeetsExpectations(50-74%) |
Fail:Unsatisfactory/BelowExpectations(0- 49%) |
|
Report
33%ofsectiongrade |
Sequencingofsectionslogicalandcoherent.Noout of sequence material or discussions. Outputresults,code,figuresappearinthesections where initially discussed Grammarandspellingerrorsarerare Internalcrossreferencingalwaysused Externalreferencingstyleappropriate |
Sequencingofsectionslogicalandcoherent. Some out of sequencing of content. Outputresults,code,figuresappearinthesections where initially discussed Grammarandspellingcontainsomeerrors Internalcrossreferencingsometimesused Externalreferencingstyleappropriate |
Sequencingofsectionsroutinelyillogical and/or incoherent, frequent out of sequencing of content. Outputresults,code,figuresroutinelydonot appear in the sections where initially discussed Grammarandspellingcontainfrequent errors Internalcrossreferencingrarely/notused Externalreferencingstyleinappropriate |
